 SQL底层执行原理详解
SQL底层执行原理详解MySQL的内部组件结构
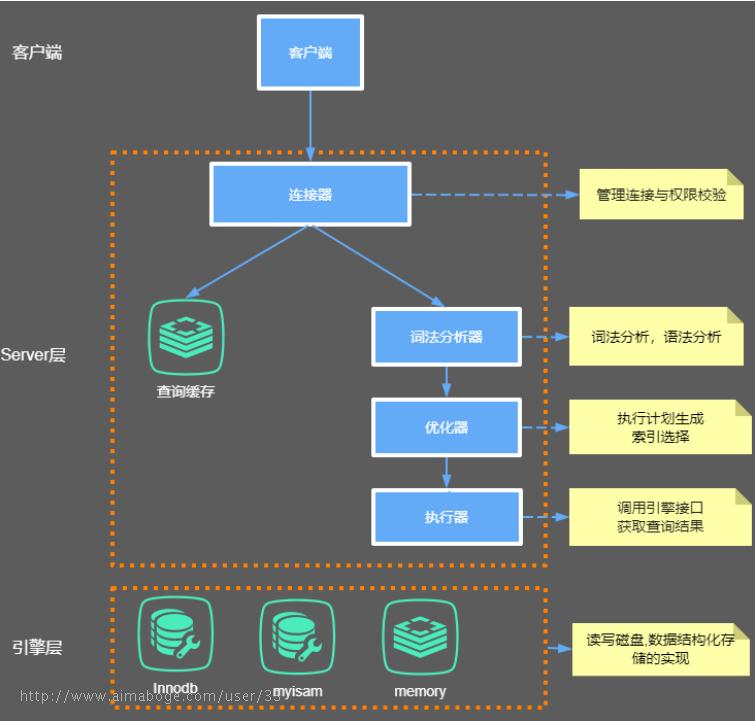
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
Server层
主要包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
Store层
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。也就是说如果我们在create table时不指定表的存储引擎类型,默认会给你设置存储引擎为InnoDB。
连接器
我们知道由于MySQL是开源的,他有非常多种类的客户端:navicat,mysql front,jdbc,SQLyog等非常丰富的客户端,这些客户端要向mysql发起通信都必须先跟Server端建立通信连接,而建立连接的工作就是有连接器完成的。
第一步,你会先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接命令一般是这么写的:
[root@192 ~]# mysql ‐h host[数据库地址] ‐u root[用户] ‐p root[密码] ‐P 3306
1、如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
2、如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。用户的权限表在系统表空间的mysql的user表中。
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它。文本中这个图是 show processlist 的结果,其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。

客户端如果长时间不发送command到Server端,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
mysql> show global variables like "wait_timeout";
mysql>set global wait_timeout=28800; 设置全局服务器关闭非交互连接之前等待活动的秒数
mysql> kill 73; # 将 id 为 73 的连接踢出去
查询缓存(mysql8.0已经移除了查询缓存功能)
分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。
根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,
词法分析器原理
词法分析器分成6个主要步骤完成对sql语句的分析
- 词法分析
- 语法分析
- 语义分析
- 构造执行树
- 生成执行计划
- 计划的执行
优化器
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
执行器
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误。
mysql> select * from test where id=1;
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
比如我们这个例子中的表 test 中,ID 字段没有索引,那么执行器的执行流程是这样的:
1. 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
2. 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
3. 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
bin-log归档
删库是不需要跑路的,因为我们的SQL执行时,会将sql语句的执行逻辑记录在我们的bin-log当中,什么是bin-log呢?
binlog是Server层实现的二进制日志,他会记录我们的cud操作。Binlog有以下几个特点:
- Binlog在MySQL的Server层实现(引擎共用)
- Binlog为逻辑日志,记录的是一条语句的原始逻辑
- Binlog不限大小,追加写入,不会覆盖以前的日志
如果,我们误删了数据库,可以使用binlog进行归档!要使用binlog归档,首先我们得记录binlog,因此需要先开启MySQL的binlog功能。
配置my.cnf
只要配置了log‐bin,就视为开启
配置开启binlog log‐bin=/usr/local/mysql/data/binlog/mysql‐bin 注意5.7以及更高版本需要配置本项:server‐id=123454(自定义,保证唯一性); #binlog格式,有3种statement,row,mixed binlog‐format=ROW6#表示每1次执行写入就与硬盘同步,会影响性能,为0时表示,事务提交时mysql不做刷盘操作,由系统决定 sync‐binlog=1
- statement
以sql语句声明形式恢复,此方式占用空间比row小
- row
以具体的二进制数据形式恢复,此方式占用空间较大
- mixed
两者混合模式
binlog里的内容不具备可读性,所以需要我们自己去判断恢复的逻辑点位,怎么观察呢?看重点信息,比如begin,commit这种关键词信息,只要在binlog当中看到了,你就可以理解为begin-commit之间的信息是一个完整的事务逻辑,然后再根据位置position判断恢复即可。binlog内容如下:
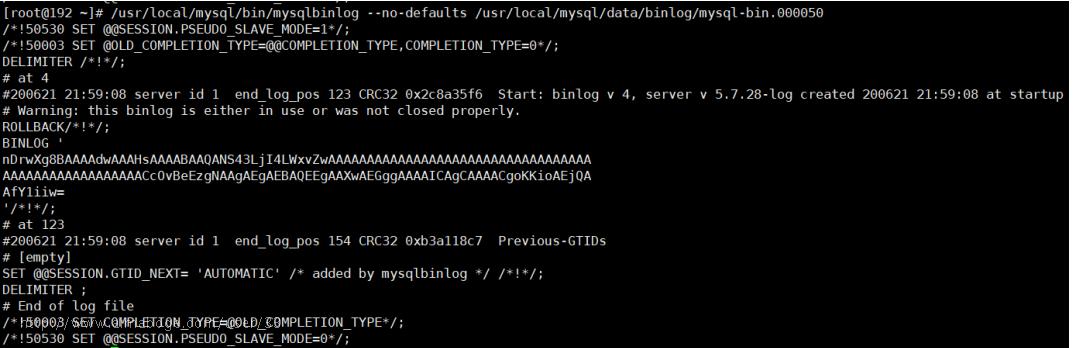
数据归档操作
从bin‐log恢复数据 恢复全部数据 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001|mysql ‐uroot ‐p tuling(数据库名) 恢复指定位置数据 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults ‐‐start‐position="408" ‐‐stop‐position="731" /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p tuling(数据库) 恢复指定时间段数据 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001‐‐stop‐date= "2018‐03‐02 12:00:00" ‐‐start‐date= "2019‐03‐02 11:55:00"|mysql ‐uroot ‐p test(数据库)
 恭喜注册成功,快来登录吧!
恭喜注册成功,快来登录吧!